External Services in CloudFoundry
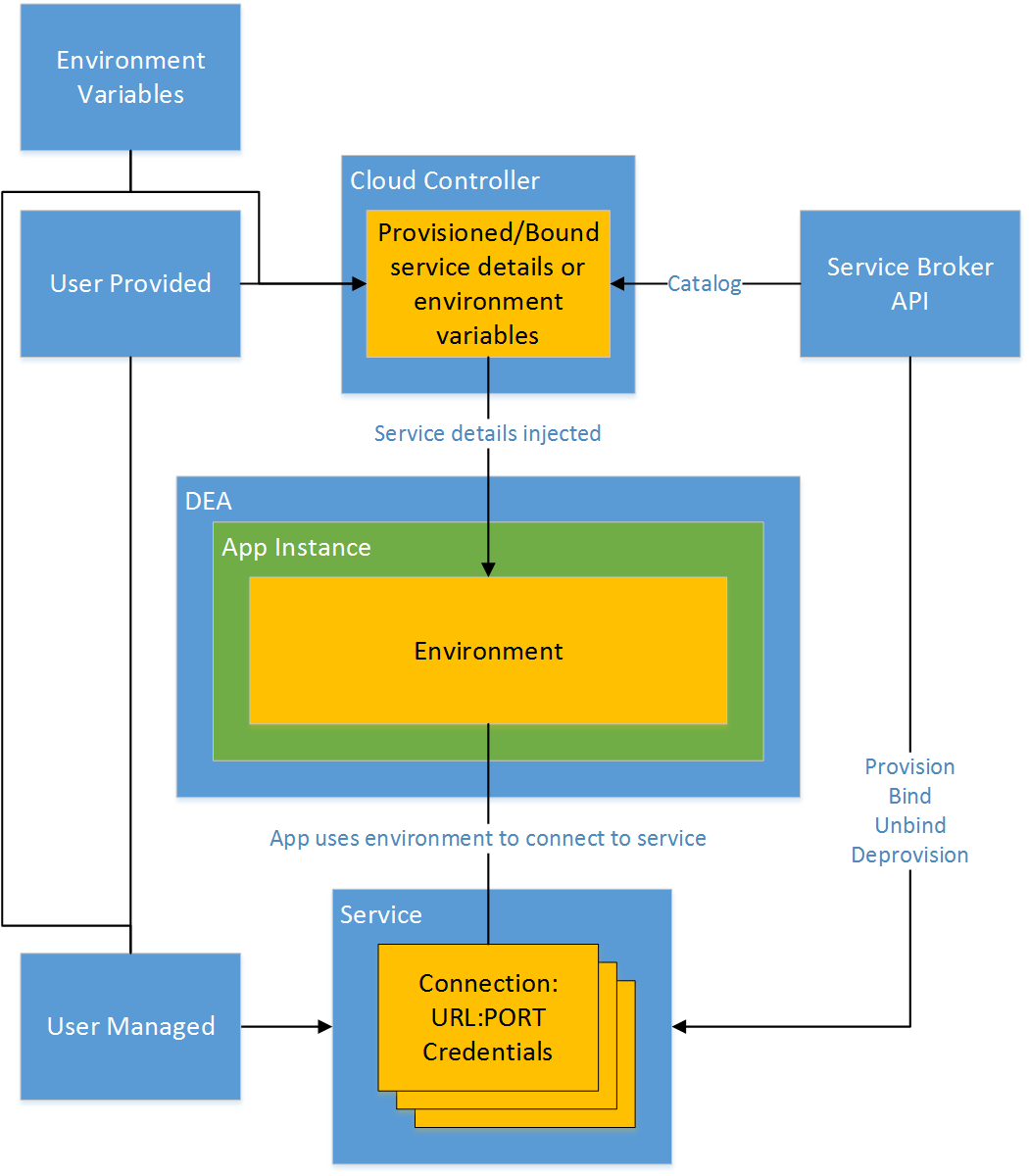
CloudFoundry, Stackato and Helion Development Platform accommodate (and encourage) external services for persistent application needs. The types of services include relational databases, like MySQL or PostgreSQL, NoSQL datastores, like MongoDB, messaging services like RabbitMQ and even cache technologies like Redis and Memcached. In each case, connection details, such as a URL, PORT and credentials, are maintained by the cloud controller and injected into the environment of new application instances.

Injection
It’s important to understand that regardless of how the cloud controller receives details about the service, the process of getting those details to application instances is the same. Much like applications use dependency injection, the cloud controller injects environment variables into each application instance. The application is written to use these environment variables to establish a connection to the external resource. From an application perspective, this looks the same whether a warden or docker container is used.
Connecting to the Service
Connecting to the service from the application instance is the responsibility of the application. There is nothing in CloudFoundry or its derivatives that facilitates this connection beyond injecting the connection parameters into the application instance container. The fact that there is no intermediary between the application instance and the service means that there is no additional latency or potential disconnect. However, the fact that CloudFoundry can scale to an indefinite number of application instances does mean the external service must be able to accommodate all the connections that will result.
Connection pooling is a popular method to reduce the overhead of creating new connections. Since CloudFoundry scales out to many instances, it may be less valuable to manage connection pooling in the application. This may increase memory usage on the application instance while consuming available connections that should be distributed among all instances.
Managed vs. Unmanaged
The Service Broker API may be implemented to facilitate provisioning, binding, unbinding and deprovisioning of resources. This is referred to as a managed service, since the life-cycle of the resource is managed by the PaaS. In the case of managed services, the user interacts with the service only by way of the CloudFoundry command line client.
In an unmanaged scenario, the service resource is provisioned outside of the PaaS. The user then provides connection details to the PaaS in one of two ways.
- The first is to register it as a service that can then be bound to application instances.
- The second is to add connection details manually as individual environment variable key/name pairs.
The three methods of incorporating services discussed in this post range from high to low touch and make it possible to incorporate any type of service, even existing services.
Use caution when designing services to prevent them from getting overwhelmed. The scalable character of CloudFoundry means that the number of instances making connections to a service can grow very quickly to an indeterminate number.
It’s very clear!
Could you show me some methods to avoid the caution you mentioned?
Thank you very much!
BRs
Zhen
Zhen,
It’s a great question about how to build data services that will scale with an increasing number of application instances. While there isn’t a specific answer, I am finding some patterns emerging. I’ll soon write more about these, but for now you can consider these
There’s a lot of detail to cover in that, but hopefully this gives you an idea about how to approach persistent data for highly scalable applications.