
Software Engineering
Developer Productivity and Vertical vs Horizontal Deployments
I’ve recently had many conversations related to developer productivity. In order for a developer to be productive,...
I'm a Software & Electrical Engineer and online entrepreneur.
I’ve recently had many conversations related to developer productivity. In order for a developer to be productive,...

One of the most significant enablers of IT and software automation has been the shift away from...
I found this article on serverwatch today: http://www.serverwatch.com/server-trends/why-kubernetes-is-all-conquering.html It’s not technically deep, but it does highlight the...
May applications require authentication to secure protected resources. While standards like oAuth accommodate sharing resources between applications,...

Container orchestration is at the heart of a successful container architecture. Orchestration takes as input a definition...

I’m interested in allowing a user to register on my site/app using their social account credentials (e.g....
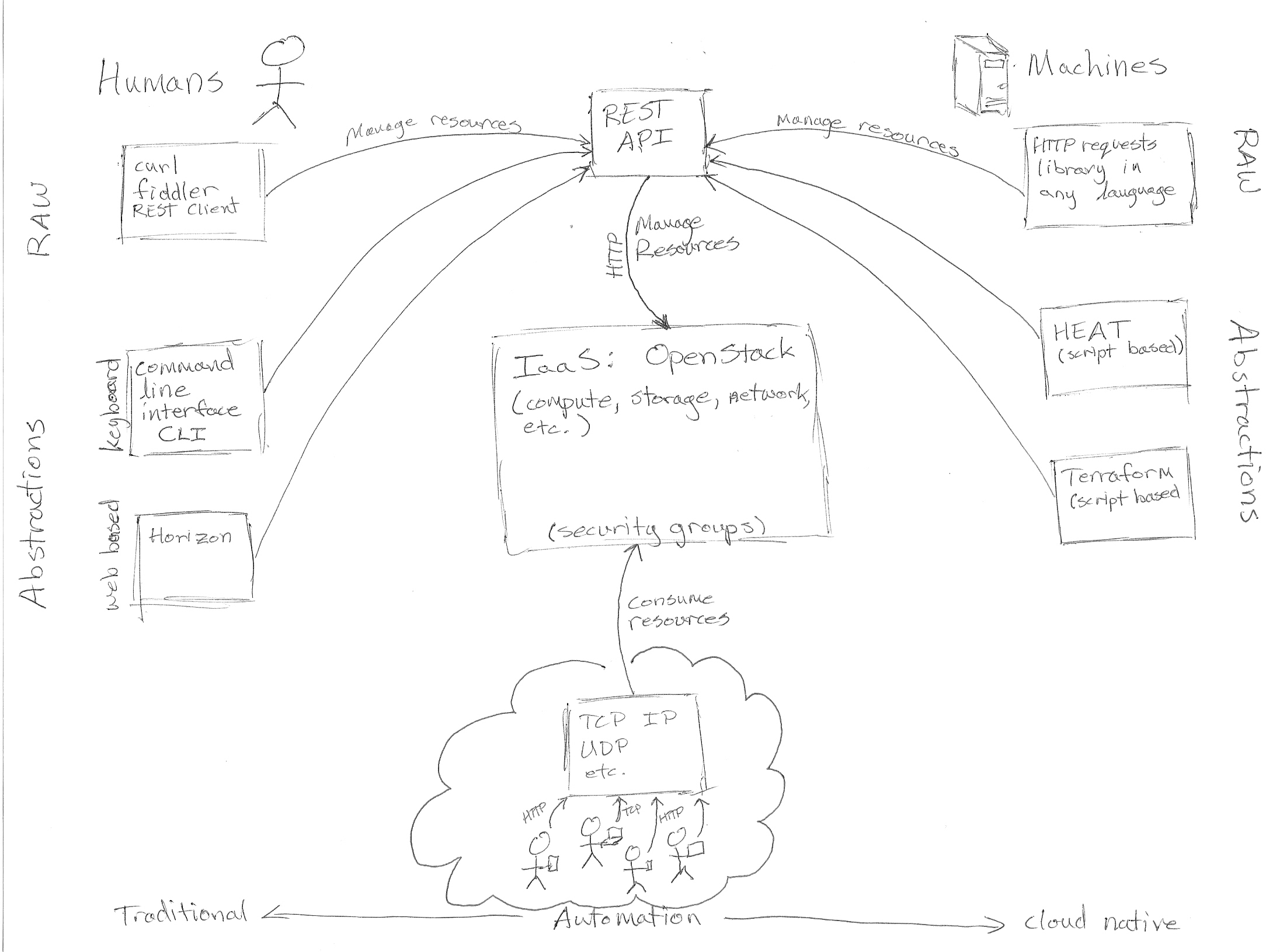
Infrastructure as a Service, like OpenStack and AWS, have made it possible to consume infrastructure on demand....
Someone asked me today whether he should use HEAT or Ansible to automate his OpenStack deployment. My...

I’ve recently had some people ask how I deploy MongoDB. For a while I used their excellent...
Today I read an article on the Wall Street Journal about the benefits of taking handwritten notes...